This page contains visualizations and explanations of different sections of data from the Excavations at
Polis data set obtained from Open Context. Decisions about where to excavate next are normally made by examining the
types of materials and artifacts found within a site based off a posed research question. These visualizations were made
to assist in making these choices. Work is done in both MATLAB and Python, and the respective repositories for each can be accessed via the buttons below. To download or view the original data set please click here.
Work Done Through MATLAB
This section is devoted to the work done on visualizing the Polis data set utilizing MATLAB. A short script titled importPolisData was written to take the excel file and import only the columns desired for this project into MATLAB. An initial clean
of the data to remove NaN values is simple enough to perform utilizing built in tools. However, to sort the data into categories
based on keywords is a bit more complex. A new function toCategorize was created to accomplish this task. The function takes a column
of data and a list of substrings to search for, searching through each entry for the related substring and converting to the proper
category if it is found. Data not put into a category is listed as “other”. After running the toCategorize function, it is possible to
visualize the data for further analysis. The code to clean and visualize the Polis data set was implemented in a way that should work for
other similar sets of data. Visuals relating to the sizes of different artifacts were also made to glean additional experience with data
science.
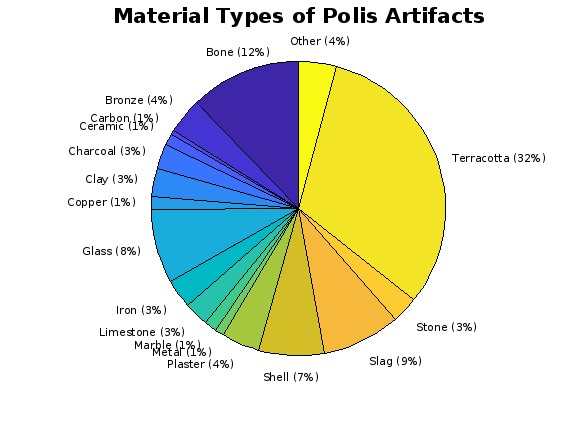
For this section regarding material type: An initial missing data clean is performed. From there,
many of the remaining data points are cleaned to present a more general view. For example, "Marble", "Marble
- White", and "Marble - Smooth White" were all combined to be a part of the "Marble" category for visualization using the toCategorize function.
As was stated above, there are large counts of individual or groups of items not significant enough to graph. Any item
category that makes up less than 1% of the total dataset is marked as "Other" for visualization purposes. These
items would crowd the visualization, and are easier to make sense of as a list.This section displays the material types
of the different artifacts found at Polis. This is useful in the process of examining what materials were being worked with
in a site.
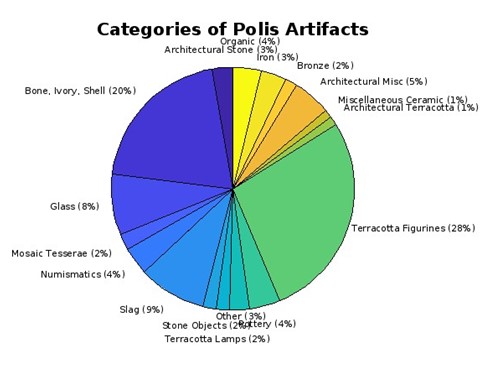
It can be useful to see a breakdown of what types of artifacts are being found within a site. This visual shows
that a large percentage of found items are terracotta statuettes. This makes sense, as Polis was used as a religious site and these figures
were often left behind as offerings to the gods.
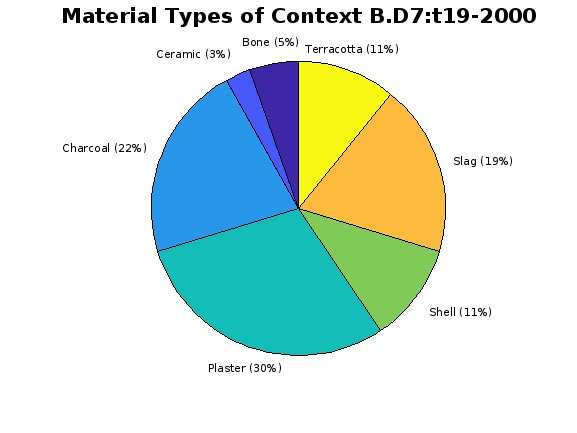
Within active archaeological digs, it can be useful to know where to dig next based on the research problem.
Visualizing the material distribution from different contexts can make it easier to know where to excavate next. Seeing which materials
appear together can help archaeologists determine the purpose of a particular area. For example, the presence of charcoal, slag, and plaster
within this context indicates that it was part of an industrial metalworking complex.
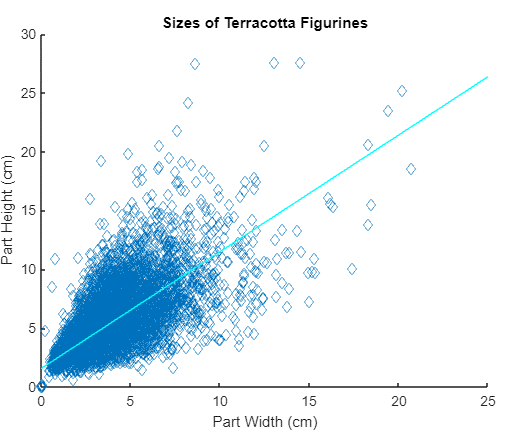
To create this scatter plot of terracotta figurine sizes, an initial clean of NaN values was performed. The few entries with greater
than 30 were removed as outliers and the remaining data was plotted. This visual is admittedly less novel than some of the others, however it
is still interesting to see how effective MATLAB is as a visual tool.
Work Done Through Python
This section outlines the work done on the Polis data set utilizing the Python programming language. The Pandas library is used for data work, with MatPlotLib being used for visualizations. The initial process is much the same,
with similar steps being taken to import the data and clean NaN values. A Python version of toCategorize was also implemented and functions much the
same as its MATLAB counterpart. The initial visualizations outlined above, such as materials pie or the per context breakdown pie, can be created here as well.
However, the Python script goes a bit further with functions that can create a histogram or a regression line between artifact material types or category types across all contexts in the site.
This is achieved by first summing the counts of two chosen variables across all contexts and then performing the necessary work to plot the results. The Python script also contains
a function to locate contexts based on minimum counts of artifact types. A short paper describing the integer linear programming problem formulated to tackle this issue was written
and is linked at the bottom of the page with the GitHub repositories for the MATLAB and Python data science work.
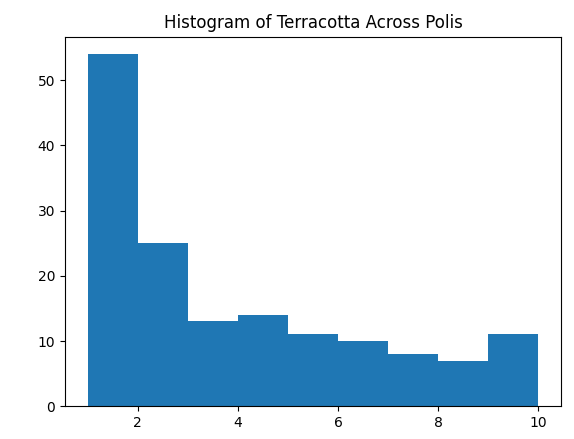
The histogram function creates a histogram of the counts of a certain type of artifact across the entire site. Some initial work is done to sum up the individual item counts
per context before generating a histogram with a user provided bin count. The normal use of a histogram is to display the frequency distribution of a variable across several data points.
The visual produced here helps with understanding how common a given artifact is across the site, which is certainly helpful from a site analysis standpoint.
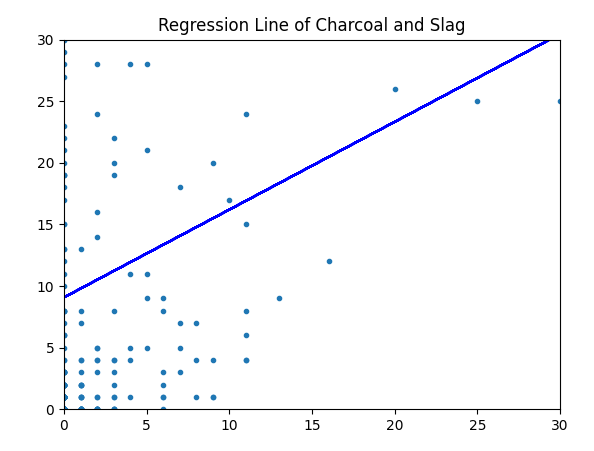
Another interesting function is the regression_line function, which creates a regression line between the counts of two material types across the site. The intention of a
regression line is to predict a y value for a given x value, showing how much and in what direction the response variable changes based on the explanatory variable. The
function itself manipulates the cleaned data into a workable format before performing and plotting a regression line. This shows how the presence of one material influences
the presence of another across the site. As is expected, there is positive correlation within the example presented here as charcoal and slag are directly relatable materials.